


Note
Click here to download the full example code
Getting Started - Accelerate Your Scripts with nvFuser¶
Authors: Christian Sarofeen Piotr Bialecki Kevin Stephano Jie Jiang Masaki Kozuki Neal Vaidya
Introduction¶
This tutorial will demonstrate how you can accelerate your networks with nvFuser. nvFuser is a Deep Learning Compiler that just-in-time compiles fast and flexible GPU specific code to reliably accelerate users’ networks automatically, providing speedups for deep learning networks running on Volta and later CUDA accelerators by generating fast custom “fusion” kernels at runtime. nvFuser is specifically designed to meet the unique requirements of the PyTorch community, and it supports diverse network architectures and programs with dynamic inputs of varying shapes and strides.
Importing Packages and Selecting a Device¶
In order to run this tutorial and see the benefits of using nvFuser, you would need to install the 1.12.0 PyTorch release as well as functorch 0.2 or newer version of them. functorch also needs networkx for its smart recomputation heuristics which you can install via pip install networkx. Additionally, a GPU is required.
import torch
import torch.nn.functional as F
import functorch
from functorch.compile import memory_efficient_fusion
from copy import deepcopy
from typing import List
import time
import functools
import random
random.seed(42)
if torch.__version__ < (1, 12, 0):
raise RuntimeError(
"PyTorch >= 1.12.0 required, but your environment uses torch=={}".format(
torch.__version__
)
)
major, minor, _ = functorch.__version__.split(".")
if int(major) == 0 and int(minor) < 2:
raise RuntimeError(
"FuncTorch >= 0.2.0 required, but your environment uses functorch=={}".format(
functorch.__version__
)
)
The Transformer Block¶
The network topology we’re going to focus on is the Transformer Block for networks like BERT. As of writing this tutorial, nvFuser provides acceleration of pointwise, reduction, and normalization operations. These simple operations are the backbone of large networks, so improving the speed of these operations can improve overall network training speed. Future releases of nvFuser will improve the performance of Linear Layers, but for now we will specifically look at the Bias-Dropout-Add-LayerNorm section of this Transformer Block.
First, let’s define the forward pass for this section of our network. For when we’ll use TorchScript on this function, we decorate the function with type information of the function parameters. This isn’t always required, but it can often help to provide this information to TorchScript because it is a strictly typed system. Since we have PyTorch’s autograd system, we don’t need to explicitly define the backwards pass.
def composite_definition(
input1: torch.Tensor,
input2: torch.Tensor,
weight: torch.Tensor,
bias1: torch.Tensor,
bias2: torch.Tensor,
normalization_axis: int,
dropout_prob: float,
) -> torch.Tensor:
bias1_out = input1 + bias1
dropout_out = F.dropout(bias1_out, dropout_prob, training=True)
norm_input = dropout_out + input2
norm_output = F.layer_norm(
norm_input, (input1.size(normalization_axis),), weight, bias2
)
return norm_output
Setup and Performance Metrics¶
Next, we initialize some inputs, parameters, and a simulated gradient output tensor for the backwards pass since we aren’t including a loss function.
# Setup initial tensors and parameters
input_size = [64, 128, 1024]
device = "cuda"
dtype = torch.float32
# Create sample inputs
input1 = torch.randn(*input_size, device=device, dtype=dtype, requires_grad=True)
input2 = torch.rand_like(input1).requires_grad_()
# Precompute a grad output tensor, for this example it's the same size
# as the inputs
grad_output = torch.rand_like(input1)
# Randomly initialize the model parameters
weight = torch.nn.Parameter(torch.randn(input_size[2], dtype=dtype, device=device))
bias1 = torch.nn.Parameter(torch.randn(input_size[2], dtype=dtype, device=device))
bias2 = torch.nn.Parameter(torch.randn(input_size[2], dtype=dtype, device=device))
parameters = [input1, input2, weight, bias1, bias2]
To produce a baseline performance we will measure the speed of our forward and backward passes in PyTorch’s default eager mode. To get accurate and comparable measurements, we perform a few warm up iterations. Then, we time many iterations of the forward and backward pass using performance counters combined with proper GPU synchronization, then compute the average iterations per second. It’s important to be very careful when measuring performance on the GPU, as we want to remove any initialization costs and need synchronization since it’s an asynchronous device. Since we will measure many variations of this problem with and without nvFuser we define a helper method called profile_workload and will use functool.partial to concisely profile the workload.
# Utility to profile the workload
def profile_workload(forward_func, grad_output, iteration_count=100, label=""):
# Perform warm-up iterations
for _ in range(3):
# Run model, forward and backward
output = forward_func()
output.backward(grad_output)
# delete gradiens to avoid profiling the gradient accumulation
for p in parameters:
p.grad = None
# Synchronize the GPU before starting the timer
torch.cuda.synchronize()
start = time.perf_counter()
for _ in range(iteration_count):
# Run model, forward and backward
output = forward_func()
output.backward(grad_output)
# delete gradiens to avoid profiling the gradient accumulation
for p in parameters:
p.grad = None
# Synchronize the GPU before stopping the timer
torch.cuda.synchronize()
stop = time.perf_counter()
iters_per_second = iteration_count / (stop - start)
if label:
print(label)
print("Average iterations per second: {:.2f}".format(iters_per_second))
We can now measure a baseline performance of PyTorch’s eager mode (without nvFuser).
# Run and profile eager mode execution on the composite definition of our
# operations.
func = functools.partial(
composite_definition,
input1,
input2,
weight,
bias1,
bias2,
normalization_axis=2,
dropout_prob=0.1,
)
profile_workload(
func, grad_output, iteration_count=100, label="Eager Mode - Composite definition"
)
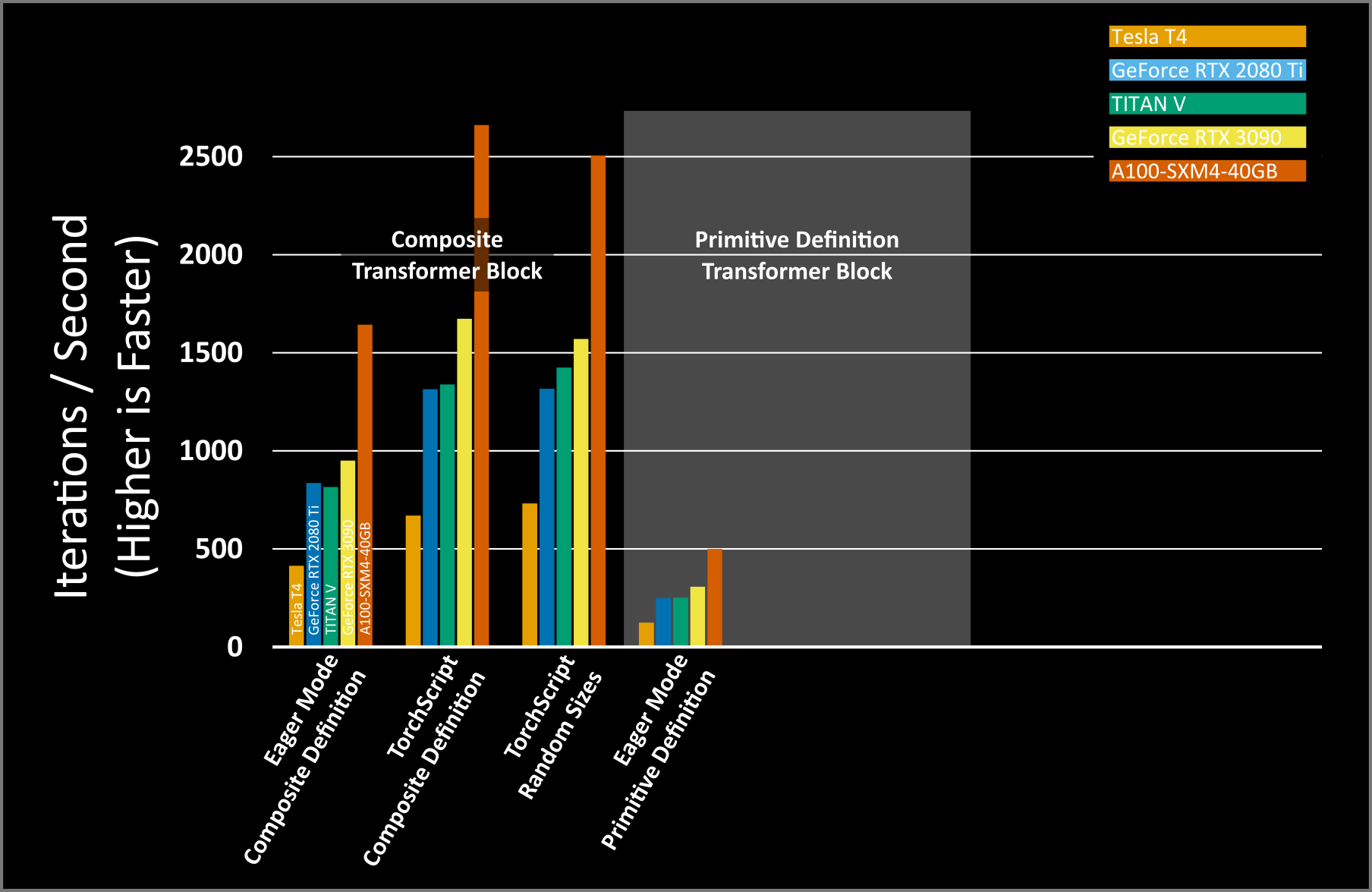
It’s important for PyTorch and nvFuser to work well across diverse GPU architectures. For our measurements we’ve run this tutorial on five GPUs ranging from consumer to enterprise grade. Our baseline geometric mean (geomean) performance across these GPUs is 850 iterations per second, plotted in the figure below.
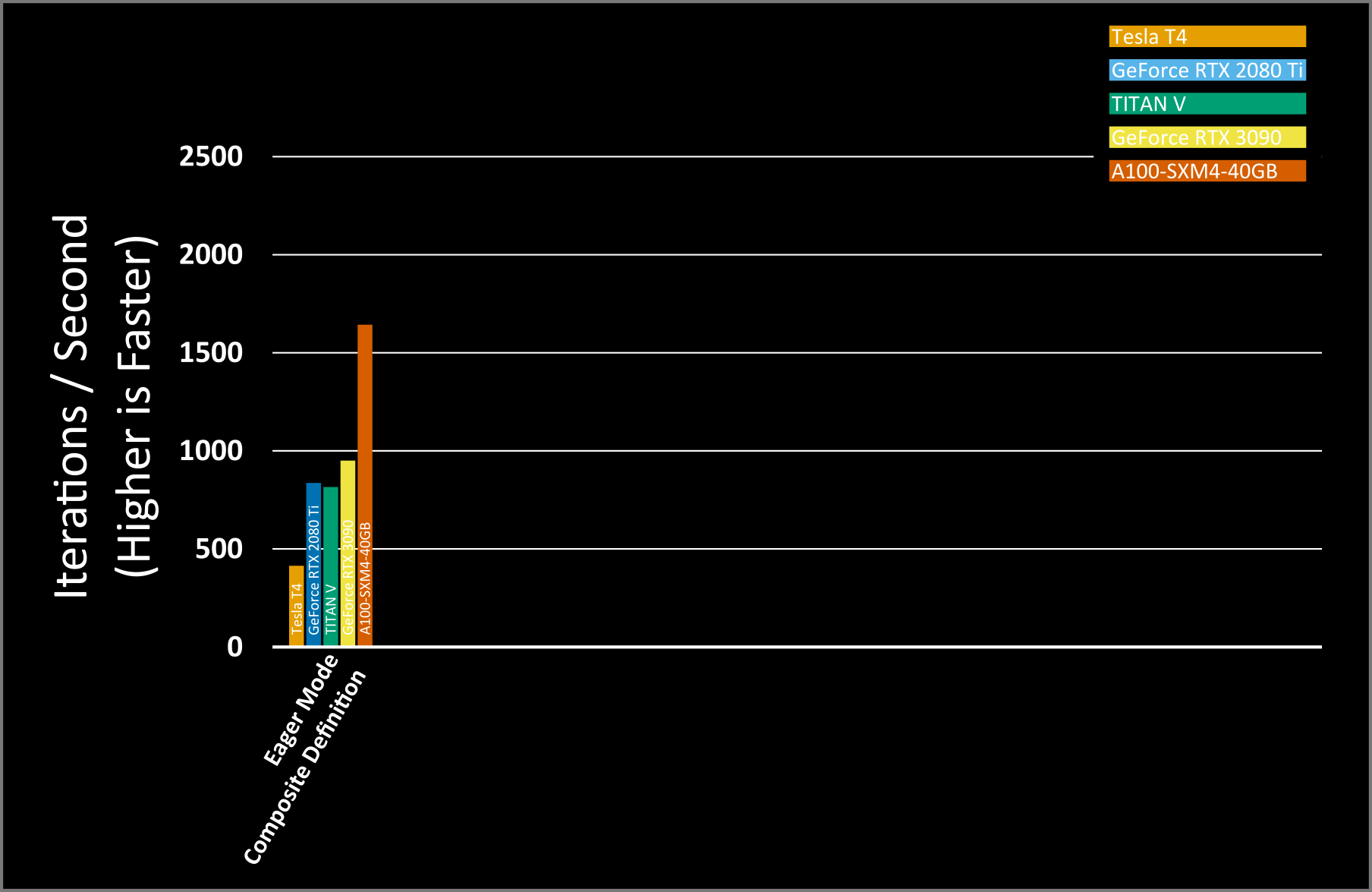
As we run different variations of this script with nvFuser, we will continue to add the results to this figure for the same GPUs.
TorchScript & nvFuser¶
nvFuser is the default fusion system in TorchScript since PyTorch version 1.12, so to turn on nvFuser we need to enable TorchScript. This will allow nvFuser to automatically generate fast kernels and take over execution of these operations. TorchScript can be a challenging system to get working, but with our current definition of our operators, all we need to do is wrap our function in the torch.jit.script compile function. We can then simply run our workload as before.
scripted_composite_definition = torch.jit.script(composite_definition)
func = functools.partial(
scripted_composite_definition,
input1,
input2,
weight,
bias1,
bias2,
normalization_axis=2,
dropout_prob=0.1,
)
profile_workload(
func, grad_output, iteration_count=100, label="TorchScript - Composite definition"
)
Before we get to the results, it is important to mention here that nvFuser does not generate the exact same sequence of random numbers, as random number generation in PyTorch is dependent on the precise parallelization scheme used for the GPU function. Therefore, if you want to validate the output of nvFuser with the output without nvFuser, it would require disabling the random number generation functions. In this example, we would simply need to change dropout_out = F.dropout(bias1_out, dropout_prob, training=True) to dropout_out = F.dropout(bias1_out, dropout_prob, training=False) as the dropout function is the only function in this example that depends on random number generation.
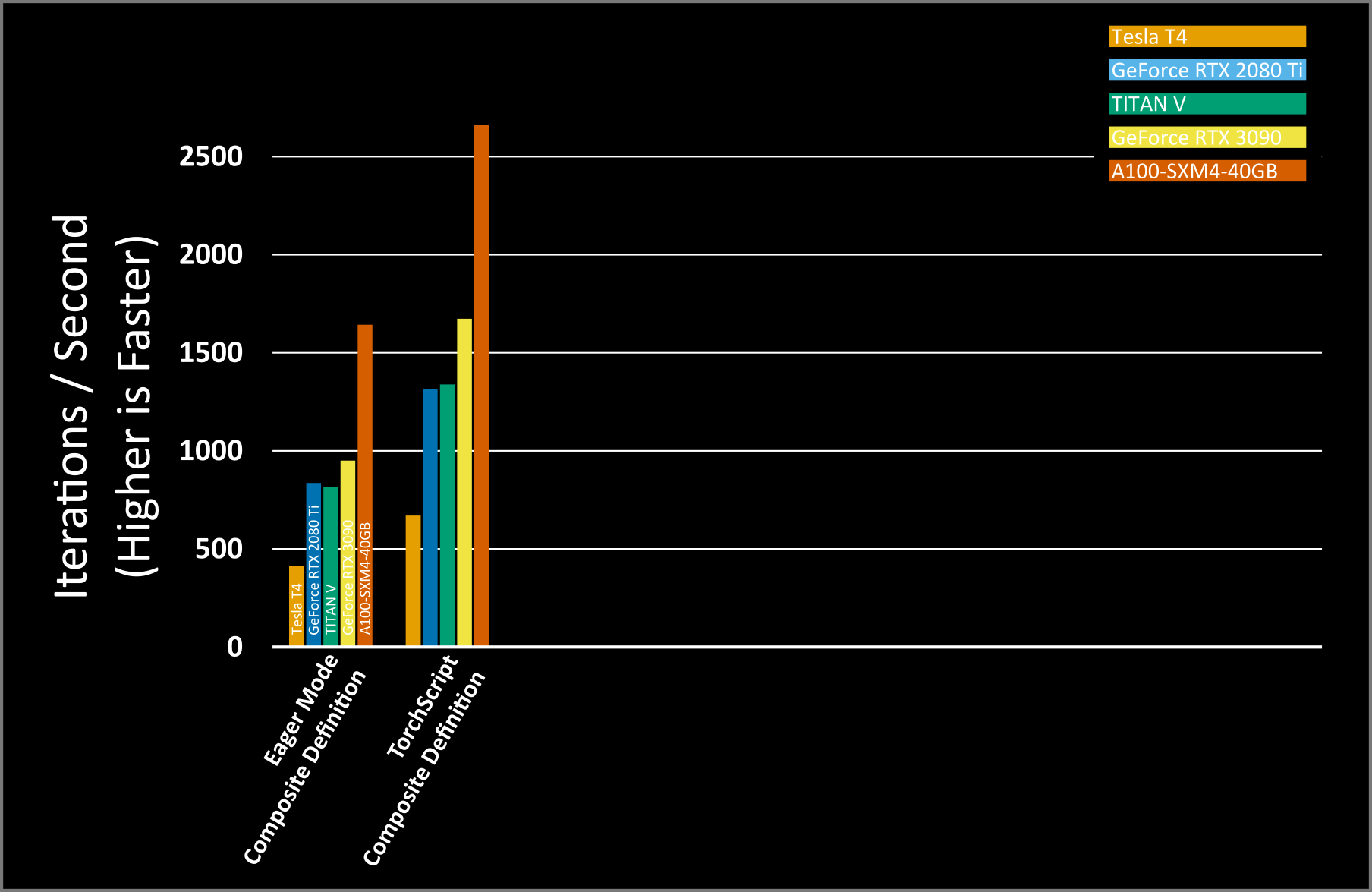
Our geomean performance with nvFuser is 1,394 images per second which is a geomean of 1.64x faster than eager mode. We did not include the time that TorchScript and nvFuser take to compile the program and GPU functions. For real end-to-end training the compile time of TorchScript and nvFuser are negligible. For example, in this tutorial the combination of TorchScript and nvFuser took around 2.4s in total to compile these high speed GPU functions.
nvFuser’s capabilities extend well beyond this initial performance gain.
nvFuser & Dynamic Shapes¶
It is challenging for Deep Learning Compilers to provide performance gains when the user changes the input sizes of the tensors. However, supporting changing shapes has always been a fundamental design criteria for nvFuser, as processing different-sized input tensors is critical to many applications like Natural Language Processing and Graph Neural Networks.
To use nvFuser on inputs that change shape from iteration, we generate new input and output gradient tensors and make a few different sizes. Since the last dimension is shared with the parameters and cannot be changed dynamically in LayerNorm, we perturb the first two dimensions of the input and gradient tensors.
SHAPE_COUNT = 20
dynamic_sizes = deepcopy(input_size)
inputs1: List[torch.Tensor] = []
inputs2: List[torch.Tensor] = []
grad_outputs: List[torch.Tensor] = []
# Create some random shapes
for _ in range(SHAPE_COUNT):
dynamic_sizes[0] = input_size[0] + random.randrange(-2, 3)
dynamic_sizes[1] = input_size[1] + random.randrange(-2, 3)
input = torch.randn(*dynamic_sizes, device=device, dtype=dtype, requires_grad=True)
inputs1.append(input)
inputs2.append(torch.rand_like(input))
grad_outputs.append(torch.rand_like(input))
No changes from before are required for running with TorchScript, we simply reuse the previous definition that we wrapped in torch.jit.script.
We’ll start as usual by performing some warm-up iterations, however we won’t show nvFuser all of the input sizes, we’ll only show one size for the warm-up.
# Perform warm-up iterations
for _ in range(3):
dynamic_input1 = inputs1[0]
dynamic_input2 = inputs2[0]
dynamic_grad_output = grad_outputs[0]
# Run model, forward and backward
output = scripted_composite_definition(
dynamic_input1,
dynamic_input2,
weight,
bias1,
bias2,
normalization_axis=2,
dropout_prob=0.1,
)
output.backward(dynamic_grad_output)
Now, we can measure the performance metrics of nvFuser as we have previously.
# Profile manually as our helper function expects static inputs
iteration_count = 100
# Synchronize the GPU before starting the timer
torch.cuda.synchronize()
start = time.perf_counter()
for i in range(iteration_count):
dynamic_input1 = inputs1[i % SHAPE_COUNT]
dynamic_input2 = inputs2[i % SHAPE_COUNT]
dynamic_grad_output = grad_outputs[i % SHAPE_COUNT]
dynamic_parameters = [dynamic_input1, dynamic_input2, weight, bias1, bias2]
# Run model, forward and backward
output = scripted_composite_definition(
dynamic_input1,
dynamic_input2,
weight,
bias1,
bias2,
normalization_axis=2,
dropout_prob=0.1,
)
output.backward(dynamic_grad_output)
# Delete the gradients to avoid profiling the gradient accumulation
for p in dynamic_parameters:
p.grad = None
# Synchronize the GPU before stopping the timer
torch.cuda.synchronize()
stop = time.perf_counter()
iters_per_second = iteration_count / (stop - start)
print("TorchScript - Random Sizes")
print("Average iterations per second: {:.2f}".format(iters_per_second))
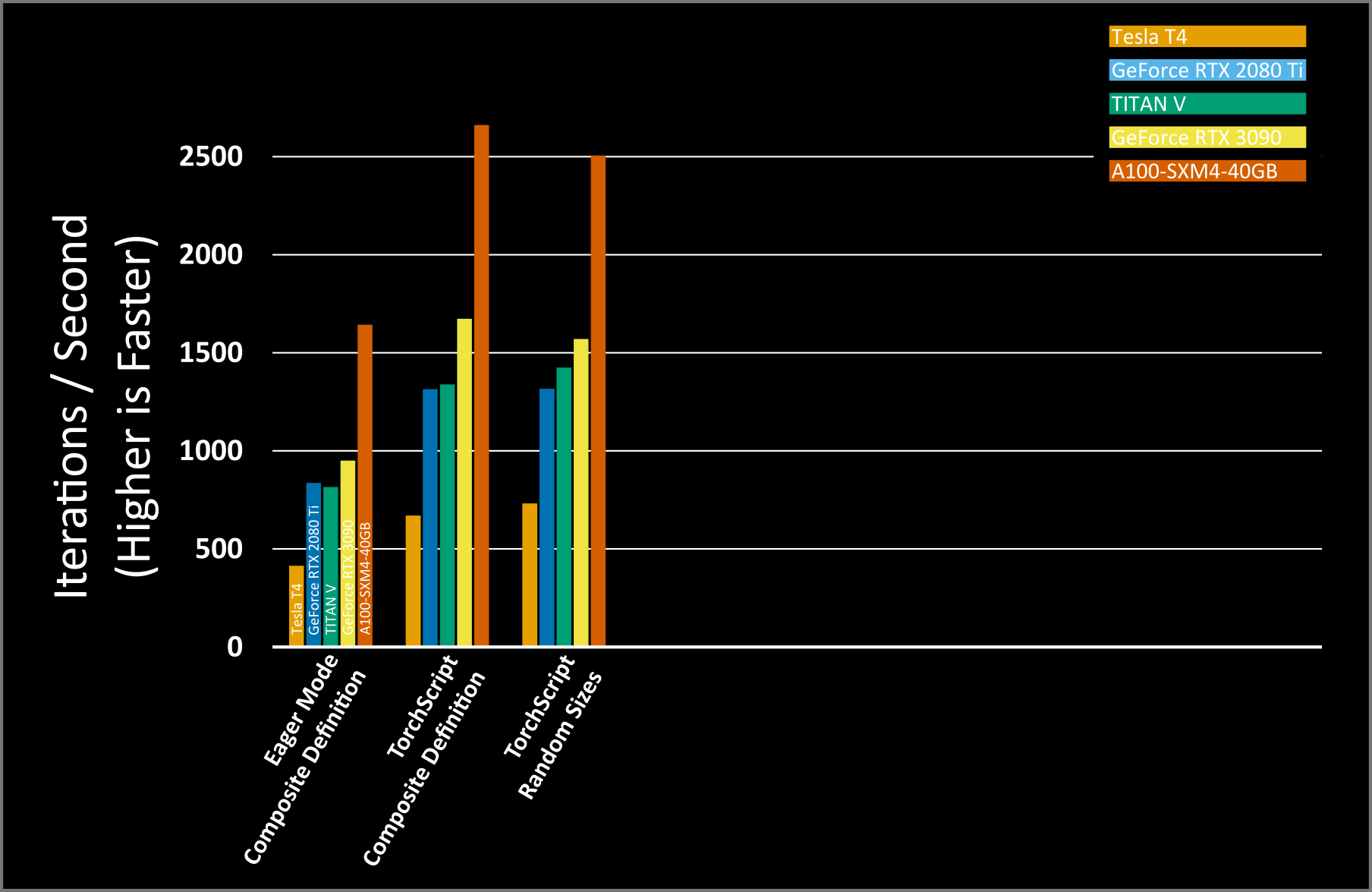
Performance across our GPUs is very similar to the previous performance seen. Only the performance of the A100 degraded slightly, but is still much higher than without nvFuser. The small change in performance of the A100 is actually related to the additional CPU overhead that dynamic shapes cause in nvFuser. nvFuser at runtime has to infer how to run the different sized kernels, so additional CPU time is consumed. This CPU time is present with all GPUs, but since the A100 runs its functions so fast this CPU overhead cannot be fully hidden by the asynchronous nature of GPU execution.
Note
Today, nvFuser in TorchScript is the only exposure of nvFuser that allows for dynamic shape changes, although we will expand this capability to other systems in the future. For more insight into how dynamic shapes are implemented in nvFuser, you can view this presentation from GTC 2021: https://www.nvidia.com/en-us/on-demand/session/gtcspring21-s31952/
Defining novel operations with nvFuser and FuncTorch¶
One of the primary benefits of nvFuser is the ability to define novel operations composed of PyTorch “primitives” which are then just-in-time compiled into efficient kernels.
PyTorch has strong performance for any individual operation, especially composite operations like LayerNorm. However, if LayerNorm wasn’t already implemented in PyTorch as a composite operation, then you’d have to define it as a series of simpler (primitive) operations. Let’s make such a definition and run it without nvFuser.
def primitive_definition(
input1: torch.Tensor,
input2: torch.Tensor,
weight: torch.Tensor,
bias1: torch.Tensor,
bias2: torch.Tensor,
normalization_axis: int,
dropout_prob: float,
keepdim: bool,
) -> torch.Tensor:
bias1_out = input1 + bias1
dropout_out = F.dropout(bias1_out, dropout_prob, training=True)
norm_input = dropout_out + input2
mean = norm_input.mean(normalization_axis, keepdim=keepdim)
diff = norm_input - mean
diff_sq = diff * diff
var = diff_sq.mean(normalization_axis, keepdim=keepdim)
pre_shift_scale_norm_output = (norm_input - mean) / torch.sqrt(var + 1e-12)
norm_output = weight * pre_shift_scale_norm_output + bias2
return norm_output
# Profile primitive definition
func = functools.partial(
primitive_definition,
input1,
input2,
weight,
bias1,
bias2,
normalization_axis=2,
dropout_prob=0.1,
keepdim=True,
)
profile_workload(
func, grad_output, iteration_count=100, label="Eager Mode - Primitive Definition"
)
While the above is mathematically equivalent to our previous definition, benchmarking our new function with the original static shape using TorchScript and nvFuser shows the iterations per second decreases – mostly due to the cost of accessing memory to save intermediate results.
The geomean iterations per second is 260 iterations per second, 3.26x slower than the composite definition in eager mode and 5.35x slower than the nvFuser composite operation! For more information on why there’s such a drastic decrease in compute speed please see this presentation from GTC 2022: https://www.nvidia.com/en-us/on-demand/session/gtcspring22-s41958/
nvFuser with TorchScript can improve the performance of this operation even though it’s defined with primitive PyTorch operations. Simply by enabling TorchScript on the new function (just like before), we can see much of the performance returns.
# Profile scripted primitive definition
scripted_primitive_definition = torch.jit.script(primitive_definition)
func = functools.partial(
scripted_primitive_definition,
input1,
input2,
weight,
bias1,
bias2,
normalization_axis=2,
dropout_prob=0.1,
keepdim=True,
)
profile_workload(
func, grad_output, iteration_count=100, label="TorchScript - Primitive definition"
)
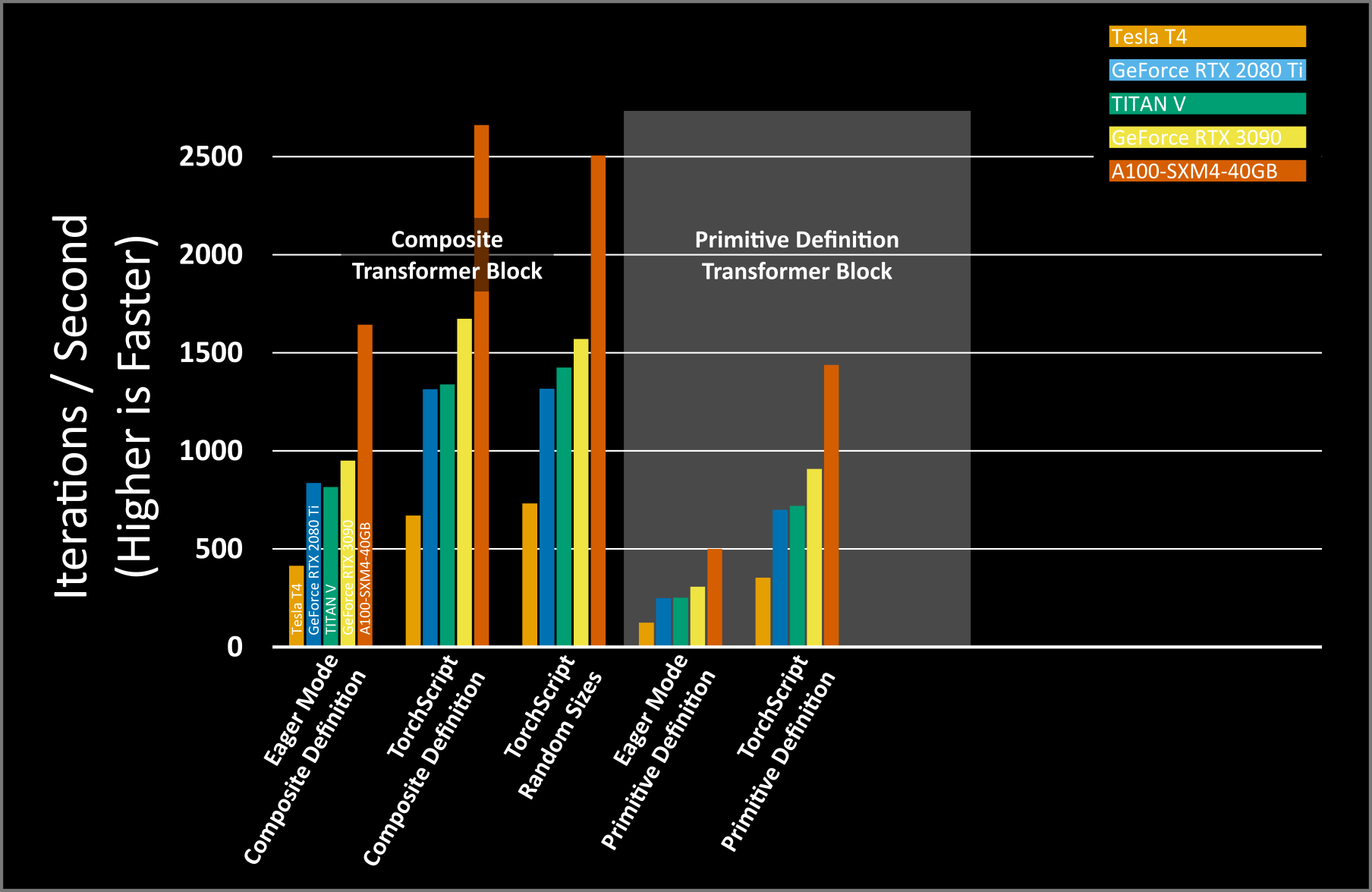
However, the performance is still slower than the original eager mode performance of the composite definition. TorchScript works well when predefined composite operations are used, however TorchScript’s application of Autograd saves all of the activations for each operator in the fusion for re-use in the backwards pass. However, this is not typically the optimal choice. Especially when chaining together multiple simple operations, it is often much faster to recompute some intermediate tensors rather than spend the time storing and retrieving several saved results from memory.
It’s possible to optimize away many of these unnecessary memory accesses, but it requires building a connected forward and backward graph which isn’t possible with TorchScript. The memory_efficient_fusion pass in FuncTorch, however, is such an optimization pass. To use this pass, we have to redefine our function to pull the constants inside (for now it’s easiest to make non-tensor constants literals in the function definition):
def primitive_definition_for_memory_efficient_fusion(
input1: torch.Tensor,
input2: torch.Tensor,
weight: torch.Tensor,
bias1: torch.Tensor,
bias2: torch.Tensor,
) -> torch.Tensor:
bias1_out = input1 + bias1
dropout_out = F.dropout(bias1_out, 0.1, training=True)
norm_input = dropout_out + input2
mean = norm_input.mean(2, keepdim=True)
diff = norm_input - mean
diff_sq = diff * diff
var = diff_sq.mean(2, keepdim=True)
pre_shift_scale_norm_output = (norm_input - mean) / torch.sqrt(var + 1e-12)
norm_output = weight * pre_shift_scale_norm_output + bias2
return norm_output
Now, instead of passing our function to TorchScript, we will pass it to FuncTorch’s optimization pass.
# Optimize the model with FuncTorch tracing and the memory efficiency
# optimization pass
memory_efficient_primitive_definition = memory_efficient_fusion(
primitive_definition_for_memory_efficient_fusion
)
# Profile memory efficient primitive definition
func = functools.partial(
memory_efficient_primitive_definition, input1, input2, weight, bias1, bias2
)
profile_workload(
func,
grad_output,
iteration_count=100,
label="FuncTorch - Primitive definition",
)
This recovers even more speed, but it’s still not as fast as TorchScripts original performance with the composite definition. However, this is still faster than running this new definition without nvFuser, and is still faster than the composite definition without nvFuser.
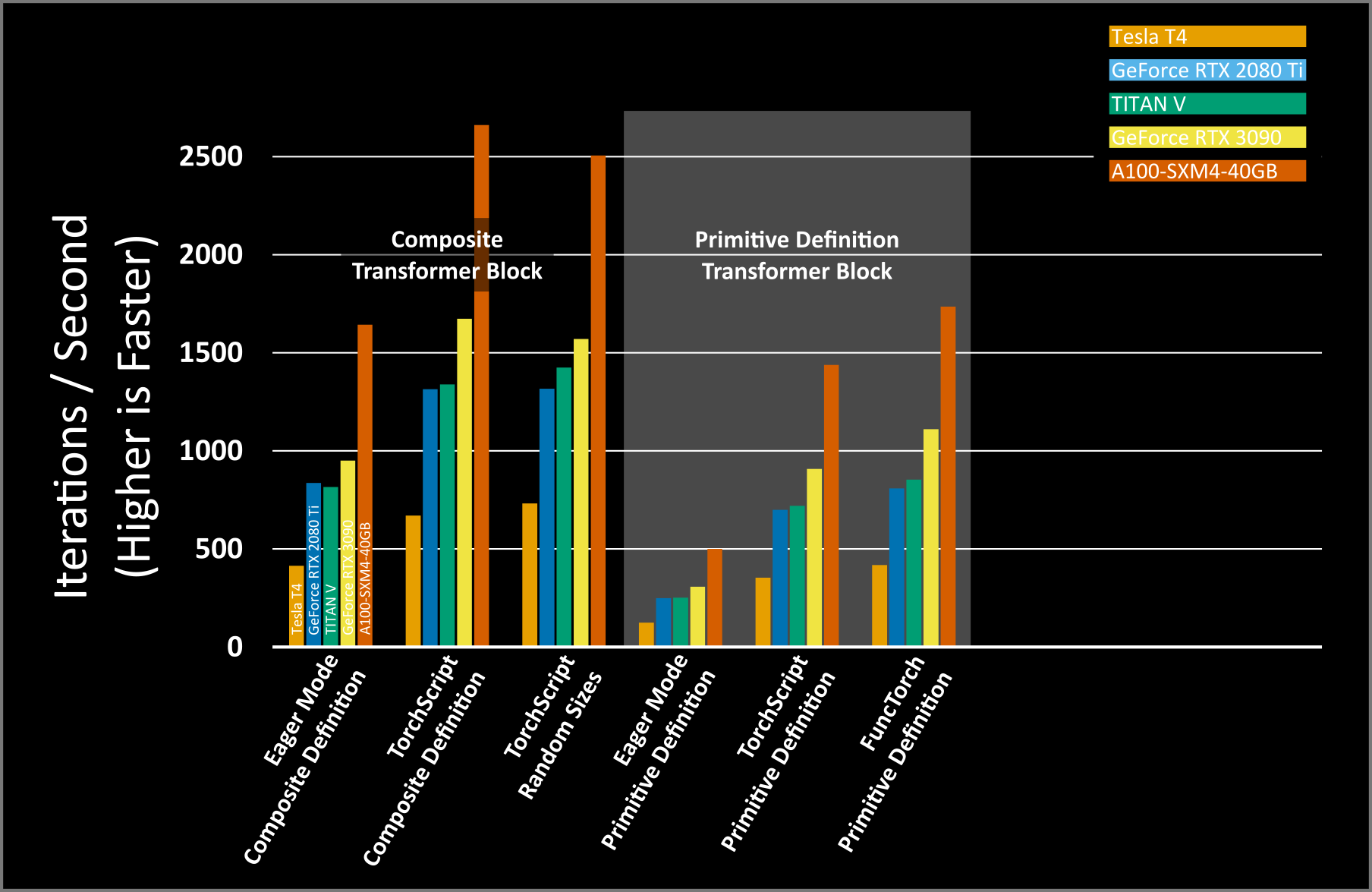
Note
FuncTorch’s memory efficient pass is experimental and still actively in development. Future versions of the API are expected to achieve performance closer to that of TorchScript with the composite definition.
Note
FuncTorch’s memory efficient pass specializes on the shapes of the inputs to the function. If new inputs are provided with different shapes, then you need to construct a new function using memory_efficient_fusion and apply it to the new inputs.
Transformer Block With a Novel Normalization¶
The ability to quickly execute chains of simple operations is important as not every operation has a composite operation defined in PyTorch. Previously, this meant researchers either had to define an entirely new operation in PyTorch – which takes a lot of time and knowledge of the lower-level PyTorch code as well as parallel programming – or writing the operation in simpler PyTorch ops and settling for poor performance. For example, let’s replace LayerNorm in our example with RMSNorm. Even though RMSNorm is a bit simpler than LayerNorm, it doesn’t have an existing compound operation in PyTorch. See the Root Mean Square Layer Normalization paper for more information about RMSNorm. As before, we’ll define our new transformer block with primitive PyTorch operations.
def with_rms_norm(
input1: torch.Tensor,
input2: torch.Tensor,
weight: torch.Tensor,
bias: torch.Tensor,
normalization_axis: int,
dropout_prob: float,
keepdim: bool,
) -> torch.Tensor:
bias_out = input1 + bias
dropout_out = F.dropout(bias_out, dropout_prob, training=True)
norm_input = dropout_out + input2
var = norm_input.mul(norm_input).mean(normalization_axis, keepdim)
pre_shift_scale_norm_output = norm_input / torch.sqrt(var + 1e-12)
norm_output = weight * pre_shift_scale_norm_output
return norm_output
As before, we’ll get a baseline by running PyTorch without nvFuser.
# Profile rms_norm
func = functools.partial(
with_rms_norm,
input1,
input2,
weight,
bias1,
normalization_axis=2,
dropout_prob=0.1,
keepdim=True,
)
profile_workload(func, grad_output, iteration_count=100, label="Eager Mode - RMS Norm")
With nvFuser through TorchScript.
# Profile scripted rms_norm
scripted_with_rms_norm = torch.jit.script(with_rms_norm)
func = functools.partial(
scripted_with_rms_norm,
input1,
input2,
weight,
bias1,
normalization_axis=2,
dropout_prob=0.1,
keepdim=True,
)
profile_workload(func, grad_output, iteration_count=100, label="TorchScript - RMS Norm")
With nvFuser through Functorch.
def with_rms_norm_for_memory_efficient_fusion(
input1: torch.Tensor, input2: torch.Tensor, weight: torch.Tensor, bias: torch.Tensor
) -> torch.Tensor:
bias_out = input1 + bias
dropout_out = torch.nn.functional.dropout(bias_out, 0.1)
norm_input = dropout_out + input2
var = norm_input.mul(norm_input).mean(2, keepdim=True)
pre_shift_scale_norm_output = norm_input / torch.sqrt(var + 1e-12)
norm_output = weight * pre_shift_scale_norm_output
return norm_output
# Profile memory efficient rms_norm
memory_efficient_rms_norm = memory_efficient_fusion(
with_rms_norm_for_memory_efficient_fusion
)
func = functools.partial(memory_efficient_rms_norm, input1, input2, weight, bias1)
profile_workload(func, grad_output, iteration_count=100, label="FuncTorch - RMS Norm")
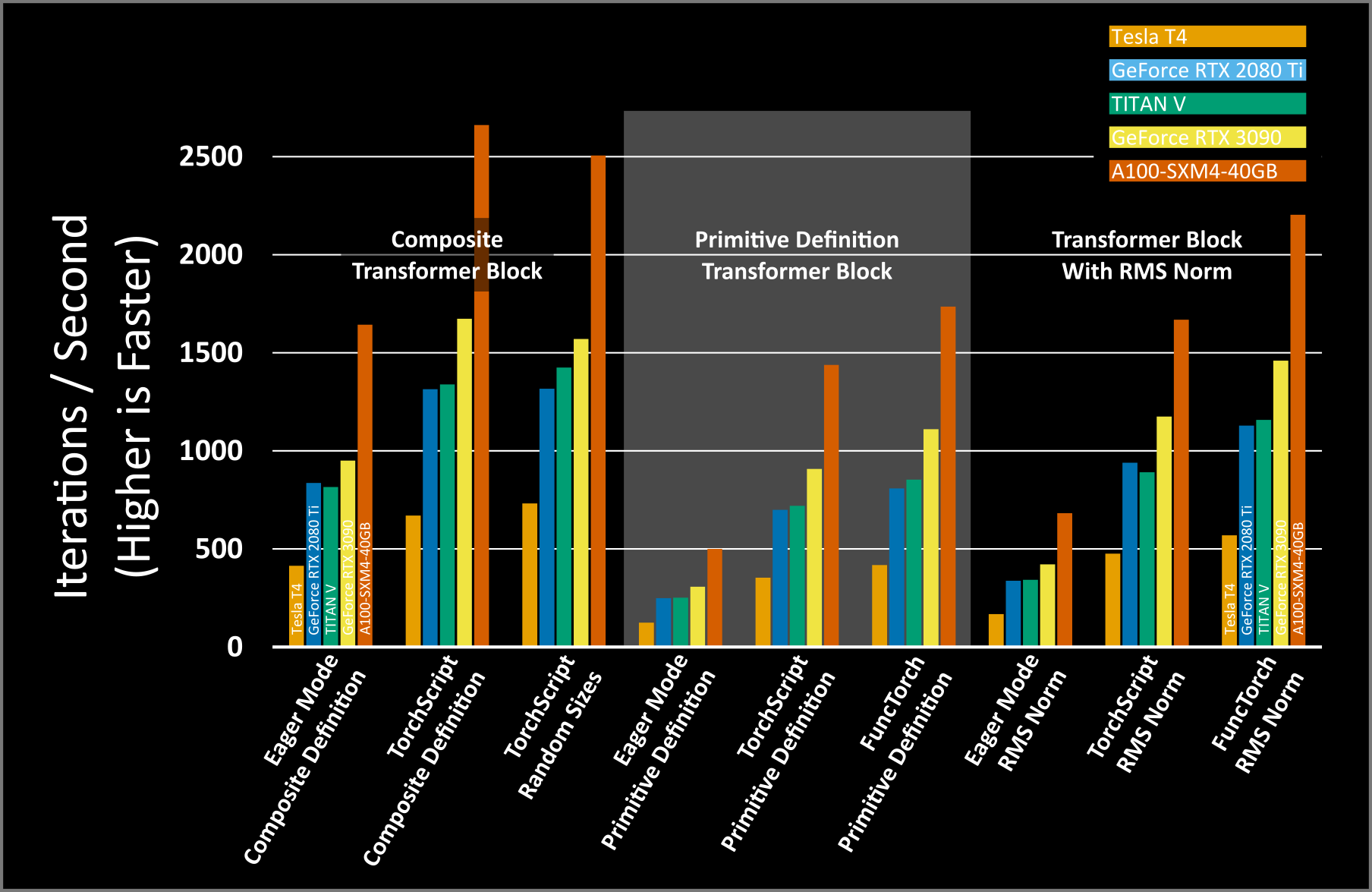
Since RMSNorm is simpler than LayerNorm the performance of our new transformer block is a little higher than the primitive definition without nvFuser (354 iterations per second compared with 260 iterations per second). With TorchScript, the iterations per second increases by 2.68x and 3.36x to 952 iterations per second and 1,191 iterations per second with TorchScript and FuncTorch’s memory efficient optimization pass, respectively. The performance of this new operation nearly matches the performance of the composite Layer Norm definition with TorchScript.
nvFuser is here to provide the ability to define novel operations in simple PyTorch and get performance that’s close to a highly optimized composite operation in PyTorch. We believe this will enable research into novel network topologies without paying for sometimes devastating effects on speed of training. nvFuser provides this unique ability as it’s able to analyze users’ programs to provide performance as fast as a highly hand tuned implementation, regardless of how the operations are defined. nvFuser still cannot support every operation in PyTorch, however its capabilities will continue to grow over time.
Total running time of the script: ( 0 minutes 0.000 seconds)
